

TLDR
- Mere correlations may fail in real-world applications, whereas causal associations tend to be more stable.
- Humanlike AI is achievable only if models can answer interventional and counterfactual questions. They can be addressed by means of causal inference.
- Causal methods can tackle AI challenges such as non-ethicality and infeasibility of experiments, biases in data and model robustness.
Welcome to the first in this series diving into all things causal inference. We will be exploring the importance of a causal approach to data and common techniques to handle data in this way!
Correlation not causation
Big data and advances in computational speed have increased the global popularity of AI technologies dramatically. Businesses and institutions are increasingly turning to machine learning to find patterns in the vast quantities of data at their fingertips. In the midst of the AI excitement, it is time to stop and ask ourselves: how good are we at predicting and explaining the world, and what aspects do our existent models lack? One of the components frequently missed is a concept of causation:
A random variable X causes a random variable Y if and only if changes in the variable X lead to changes in variable Y. Put it differently, Y “listens”to X [1].
Modern machine learning models often capture correlations between variables and fail to inform us the causes behind these correlations. If detected associations are non-causal, they are spurious and may not hold out-of-sample. Although causal relationships can change over time too, they tend to be more stable than correlations since they shape a data-generating process of variables. Besides, causal relations help to understand the underlying system. The applications of this could be critical when applying machine learning to our contemporary world, particularly in fields such as medicine and economic policy. Fortunately, the scientific field of casual inference is gaining traction, with several specific researchers leading the cause over the past few decades.
Humanlike AI
If we are going to develop machines that think like with humans, causal inference can play a significant part in this process. Traditional (non-causal) ML models are not enough because they are related to merely seeing data and drawing patterns from it. This is a useful but basic ability of people’s brain that does not reflect our full cognitive power. Such traditional models are called observational and answer the following question: how does Y change if I observe changes in X? To design AI that mirrors human intelligence, we need to teach machines to intervene and imagine, which is possible with causal models.
Interventional causal models answer the following question: what happens with Y if I impose changes in X? Hence, they relate to finding patterns when we perform actions in the world as opposed to observing it. Imaginative (counterfactual) causal models go further and show how Y would have changed if X had been changed, given that I have observed the past. This implies imagining the worlds that have never happened – one of the cognitive abilities that makes us so different from other animals. The levels of association (observation), intervention and counterfactuals define the ladder of causation (Figure 1) - the term introduced by Judea Pearl [1]. Most of the current ML models perform at the first rung, so there is a long way to go to develop the true AI.
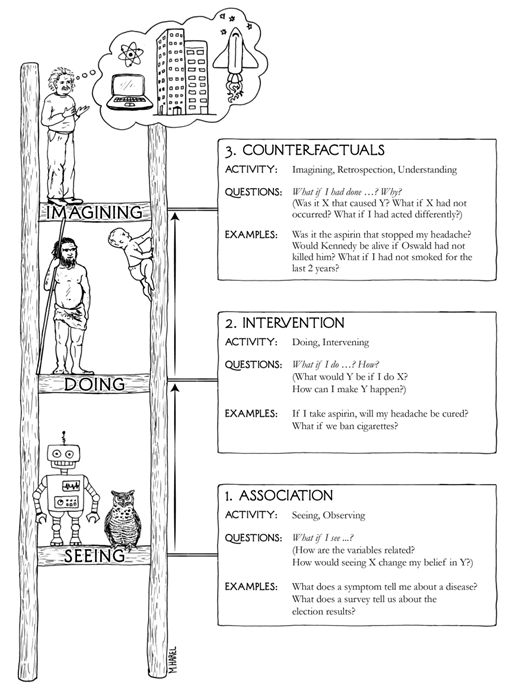
Resolving biases
The importance of causality also becomes apparent when non-causal associations lead to biased decisions due to a common cause of variables (a confounding variable). Consider an example when we ask old people to choose freely to increase walking activity to increase their life expectancy. Next, suppose we observe that people who walk more tend to prolong their life. However, what if healthier people tend to improve their walking activity? Then, the initial state of health causes both the treatment acceptance and resulting longevity. This illustrates that in observational studies an association between a treatment and an outcome can appear merely due to the confounding variable (e.g. “initial health conditions”) which introduces a confounding bias. This bias appears not only in medical research but also in studies related to nationality, race and sex, where it can lead to discriminative decisions [2].
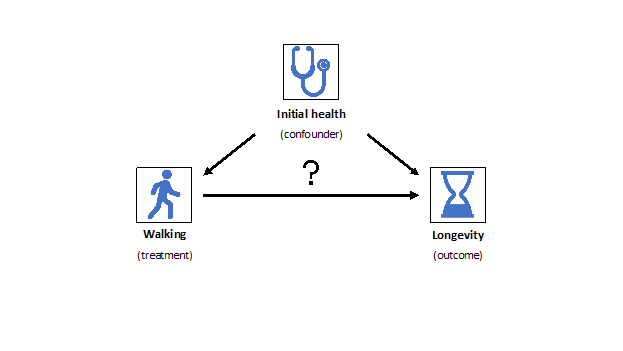
How could we perform our healthcare study to remove the confounding effect and identify a true causal link between walking and longevity? A gold standard practice in medicine is to conduct a Randomized Controlled Trial (RCT) introduced by R. Fisher [3]. The idea is to assign a treatment randomly, that is, regardless of patients’ features, which implies absence of confounding. Hence, the bias becomes eliminated, and any difference between the treatment and the control group stems solely from walking. Albeit RCTs are effective, they are not always ethical. If we conducted research on how smoking affects lung cancer probability, it would clearly be unethical to obligate some people to smoke. Finally, specific experiments are not feasible at all, e.g. those that would imply random assignment of genetic characteristics. What should we do in such cases?
The solution would be to estimate causal effects using causal inference techniques. In essence, causal models mimic RCTs using solely observational data by doing the following:
- Identify causal relations between all relevant variables;
- Impose changes on treatment;
- See how the outcome responds to these changes accounting for confounding and other potential biases.
In the walking example, if we just observed data, we would see changes in treatment being associated with walking activity. However, if we accounted for initial health conditions to estimate the effect correctly, this relation could disappear and would lead us to a correct medical recommendation.
Conclusion
Unfortunately, there are situations when even causal inference tools cannot estimate a causal relationship. This is known as an identifiability problem. Nevertheless, in the big data era, causal inference can be extremely important to distinguish between the signal and the noise whenever it is applicable. Researchers in medicine, economics, marketing and other fields have been using causal models to identify true links between variables and develop fairer models. The ability to perform interventions and ask counterfactual questions takes us one step closer to humanlike AI. Therefore, causal inference deserves higher attention from a data science community.
In the next part of the introduction, we will dig deeper into causal graphs, which are an essential component of causal inference.
*Disclaimer - All views in this article belong to Maksim Anisimov and are not a reflection of his employer or wider affiliations.*
References
[1]Judea Pearl and Dana Mackenzie. 2018. The Book of Why: The New Science of Cause and Effect (1st. ed.). Basic Books, Inc., USA.
[2] Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2019). A survey on bias and fairness in machine learning. arXiv preprint arXiv:1908.09635. Available at https://arxiv.org/pdf/1908.09635.pdf.
[3] Fisher, R. A. (1992). Statistical methods for research workers. In Breakthroughs in statistics (pp. 66-70). Springer, New York, NY.